KORE
Enhancing Knowledge Injection for Large Multimodal Models via Knowledge-Oriented Controls
ICML 2026 🔥
Teaser
"Knowledge-Oriented Control, Accurate Adaptation and Powerful Retention!"
– Evolving Knowledge Injection
Introduction
Large Multimodal Models encode extensive factual knowledge in their pre-trained weights. However, its knowledge remains static and limited, unable to keep pace with real-world developments, which hinders continuous knowledge acquisition. Effective knowledge injection thus becomes critical, involving two goals: knowledge adaptation (injecting new knowledge) and knowledge retention (preserving old knowledge). Existing methods often struggle to learn new knowledge and suffer from catastrophic forgetting. To address this, we propose KORE, a synergistic method of KnOwledge-oRientEd augmentations and constraints for injecting new knowledge into large multimodal models while preserving old knowledge. Unlike general text or image data augmentation, KORE automatically converts individual knowledge items into structured and comprehensive knowledge to ensure that the model accurately learns new knowledge, enabling accurate adaptation. Meanwhile, KORE stores previous knowledge in the covariance matrix of LMM's linear layer activations and initializes the adapter by projecting the original weights into the matrix's null space, defining a fine-tuning direction that minimizes interference with previous knowledge, enabling powerful retention. Extensive experiments on various LMMs, including LLaVA-v1.5-7B, LLaVA-v1.5-13B, and Qwen2.5-VL-7B, show that KORE achieves superior new knowledge injection performance and effectively mitigates catastrophic forgetting.
KnOwledge-oRientEd Augmentations and Constraints
Overview of KORE, a synergistic method for knowledge-oriented augmentation and constraint. KORE-Augmentation automatically converts each piece of knowledge into profound and structured knowledge. KORE-Constrain minimizes interference with previous knowledge by initializing an adapter with null space that stores covariance matrix of previous knowledge.
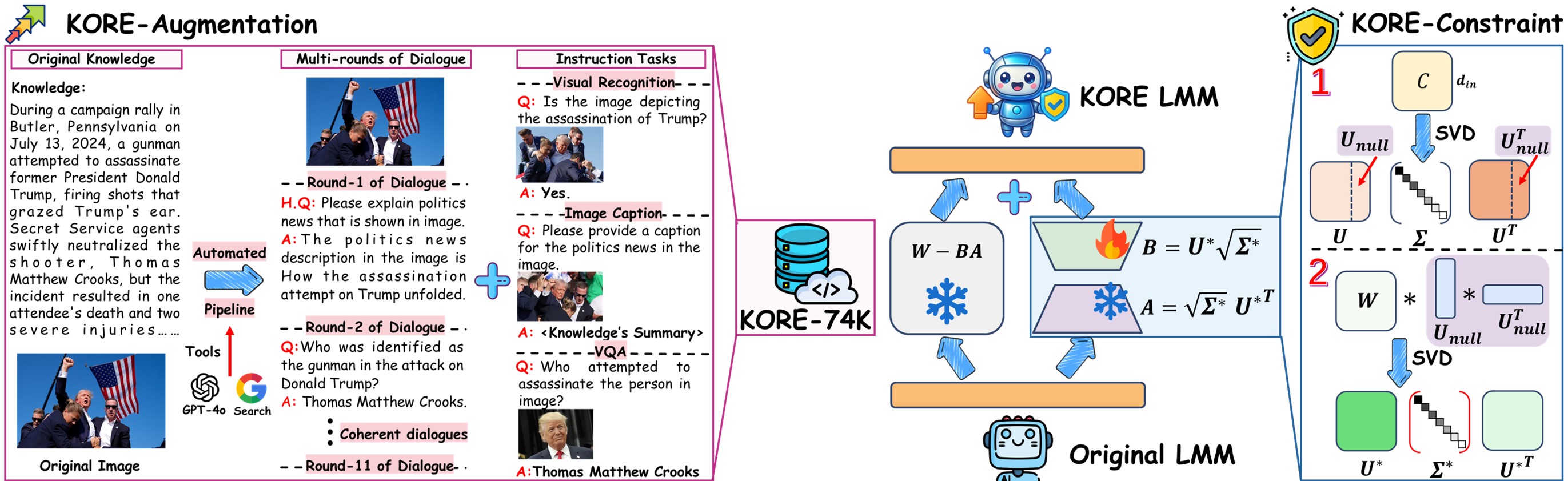
KORE-Augmentation
We observe that KORE-Augmentation augments the original knowledge into multi-rounds dialogues data (forming the trunk) and instruction tasks data (forming the branches), thereby constructing a comprehensive and higher-level knowledge tree (Left part of Figure 3) that supports superior generalization and internalization of new knowledge. KORE-Augmentation moves beyond enabling models to accurately fit training data for “data memorization”. Instead, it focuses on helping the model comprehend and reason about the inherent logic and associations within the knowledge itself. This enables the model to think, internalize new knowledge, and effectively extract and manipulate the learned knowledge, thereby achieving real “knowledge internalization”.

KORE-Constraint
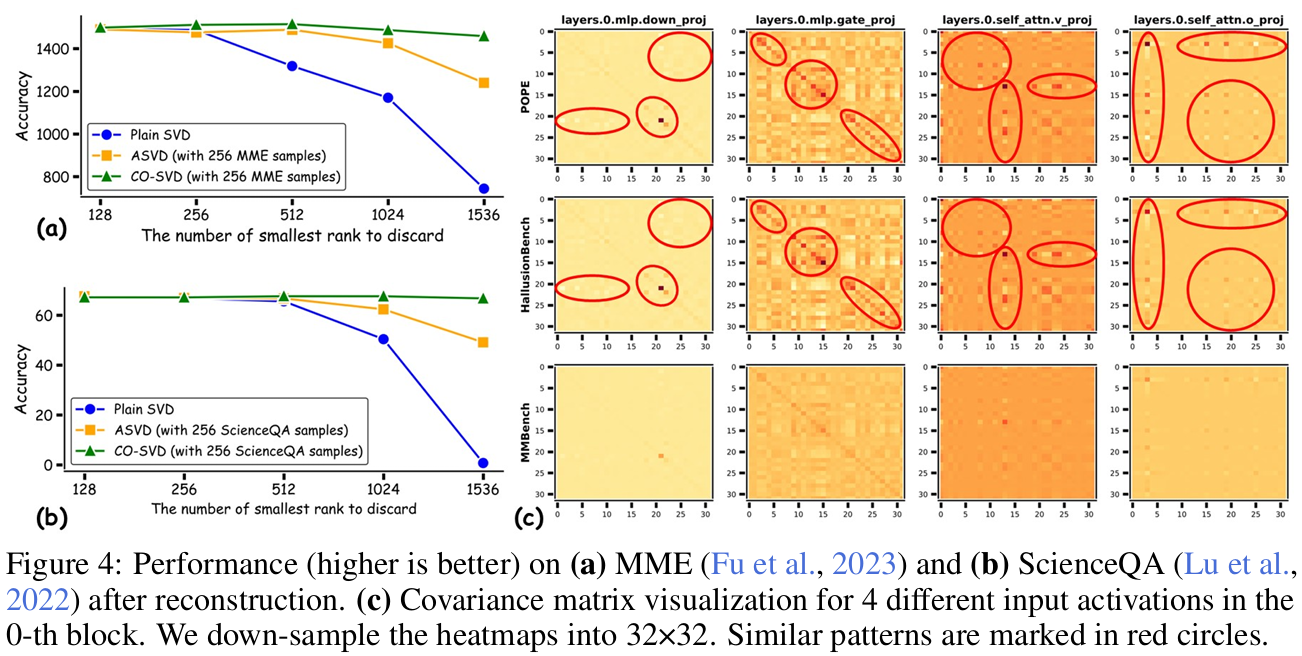
Our analysis reveals two key findings: (1) Figure 4 (a) and (b) demonstrate that CO-SVD exhibits superior performance retention compared to Plain SVD, ASVD and suggest that multimodal knowledge can be effectively captured and stored in covariance matrix. (2) Figure 4 (c) shows that covariance matrices of linear layer inputs share similar outlier patterns for related tasks (POPE and HallusionBench), but differ from unrelated ones (MMBench), indicating that distinct tasks exhibit different outlier distributions in the covariance matrix. To build a multi-dimensional covariance matrix for KORE, we finally sample 64 examples per category from OneVision's single-image subset (General, Doc/Chart/Screen, Math/Reasoning, General OCR).
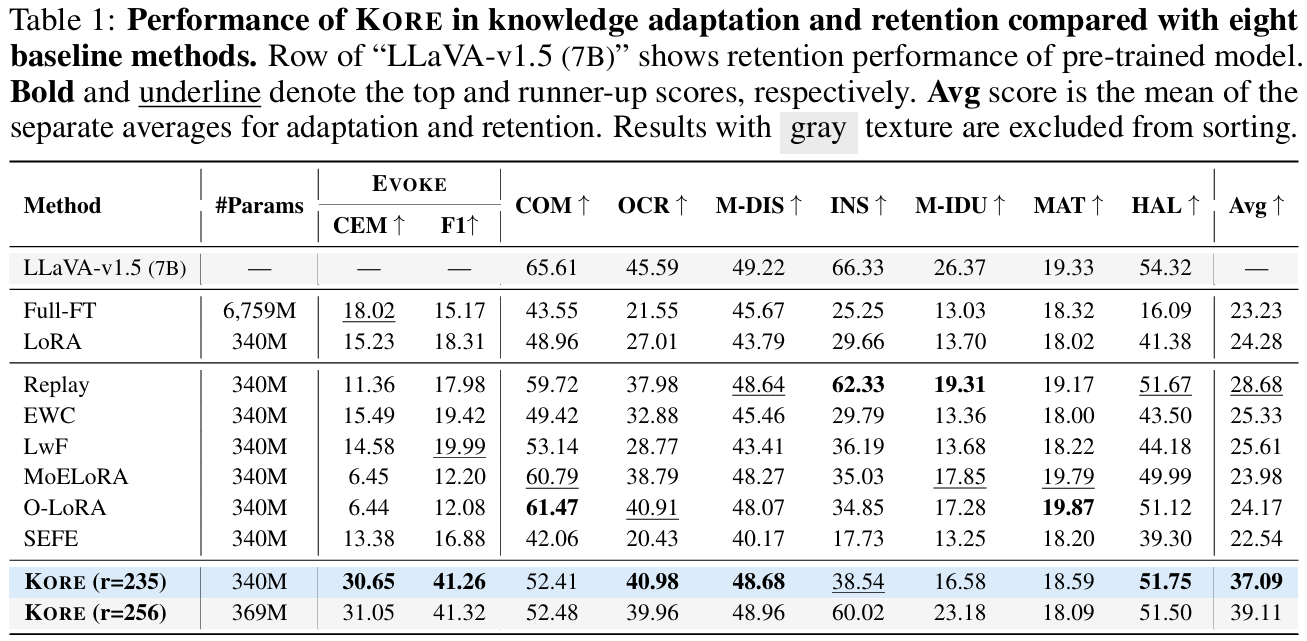
Analysis of Main Results
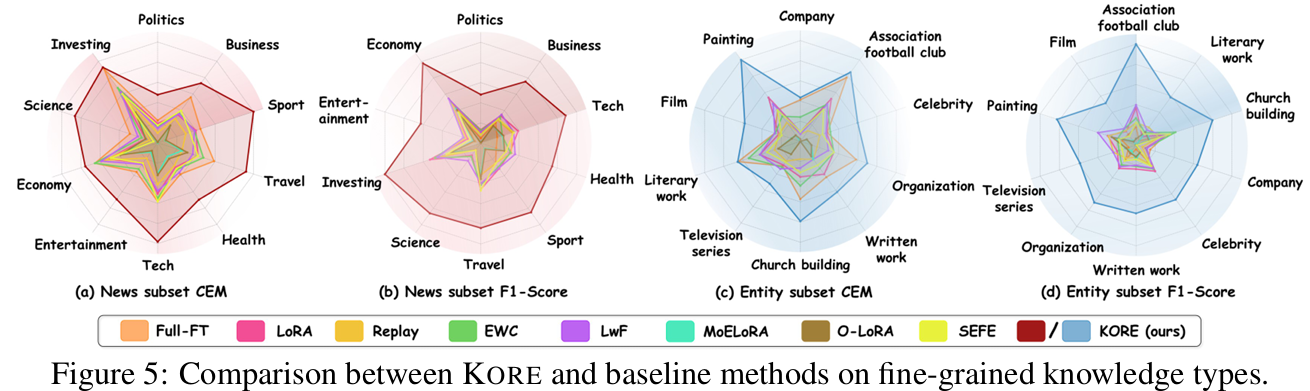
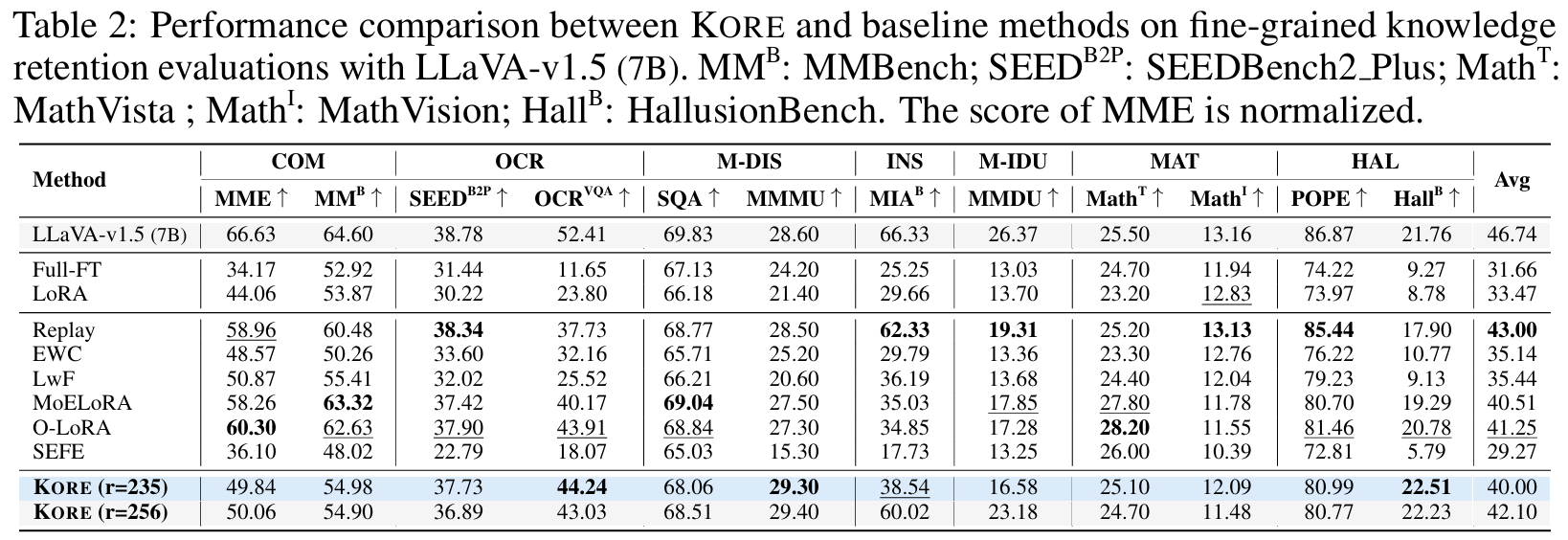
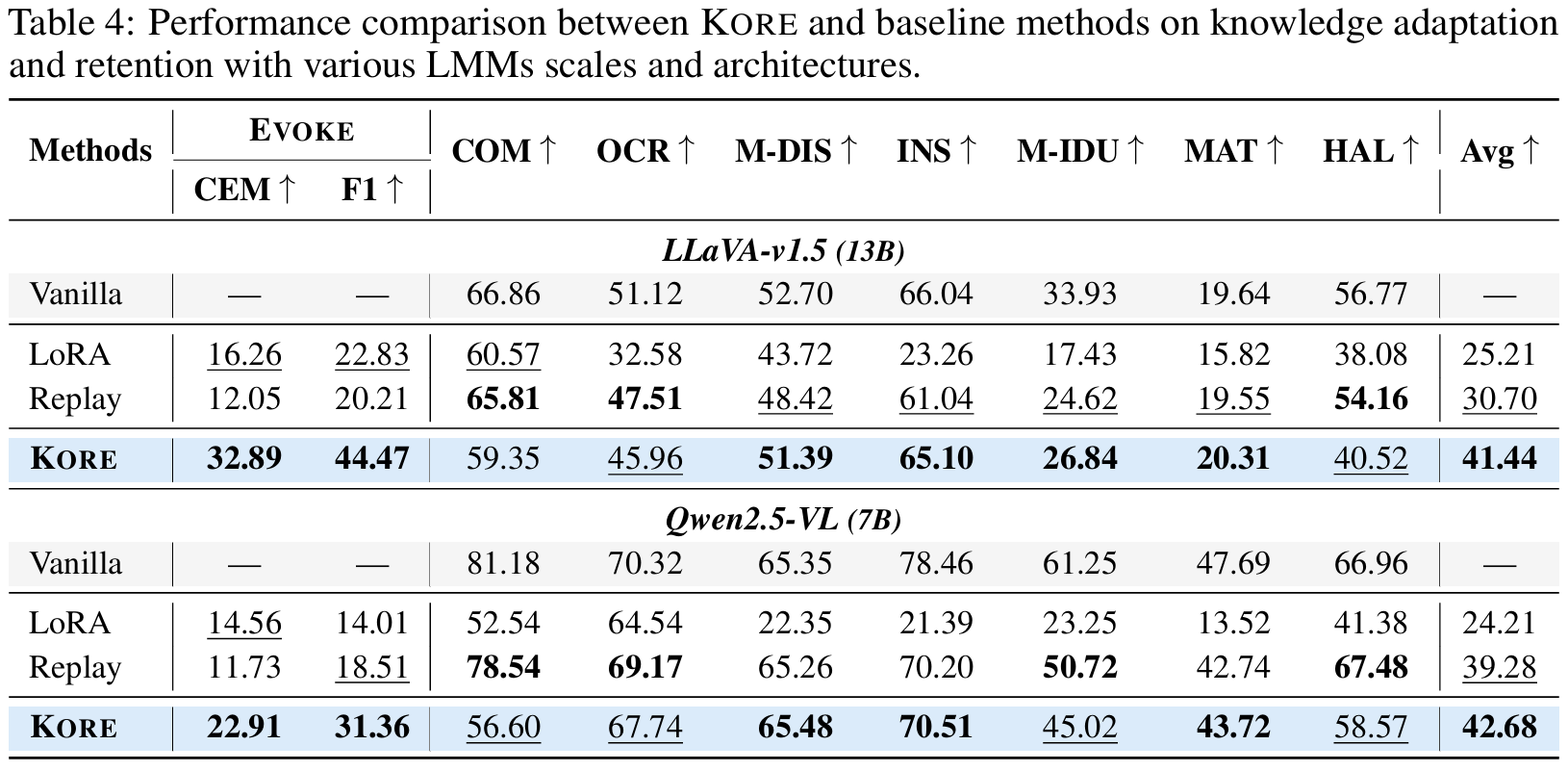
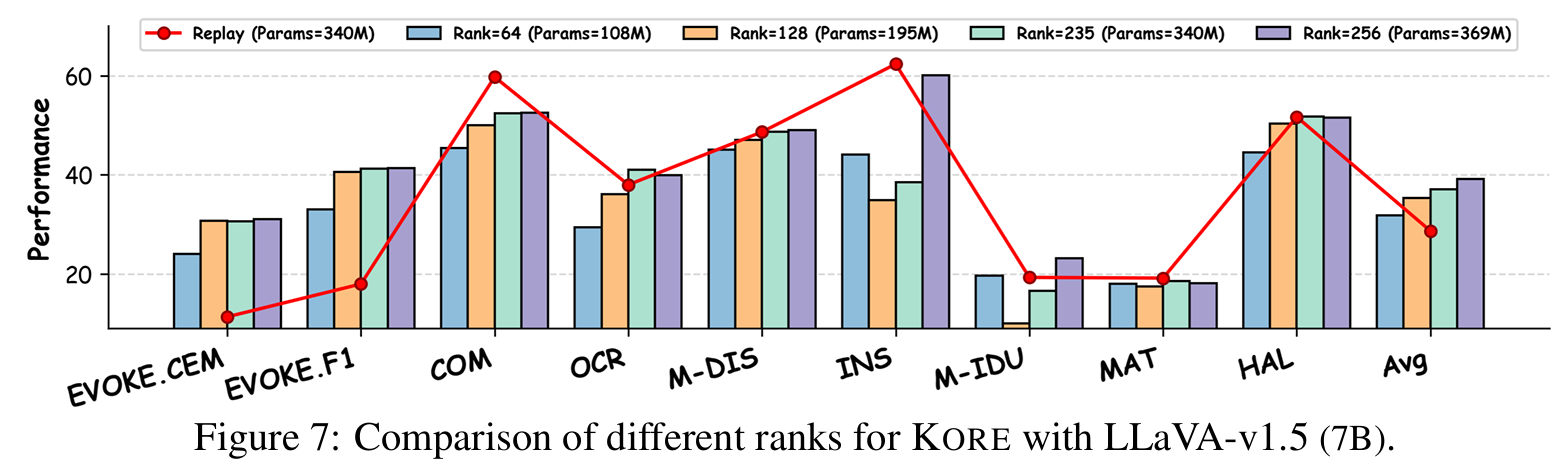
Analysis of Various LMM scales and Architectures
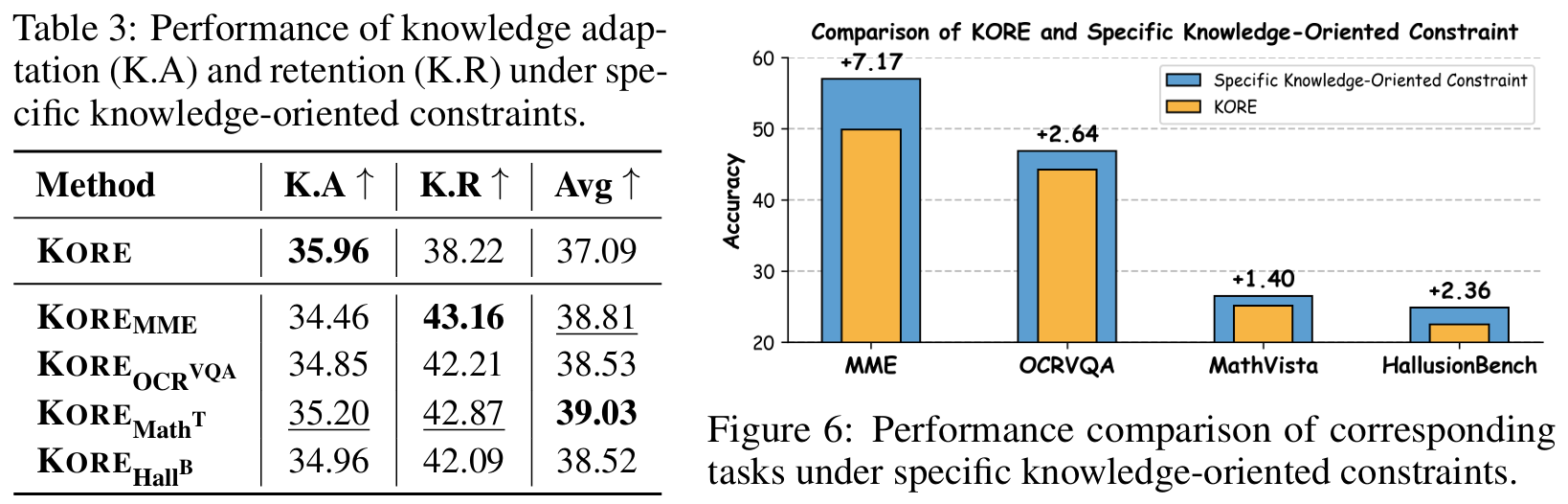
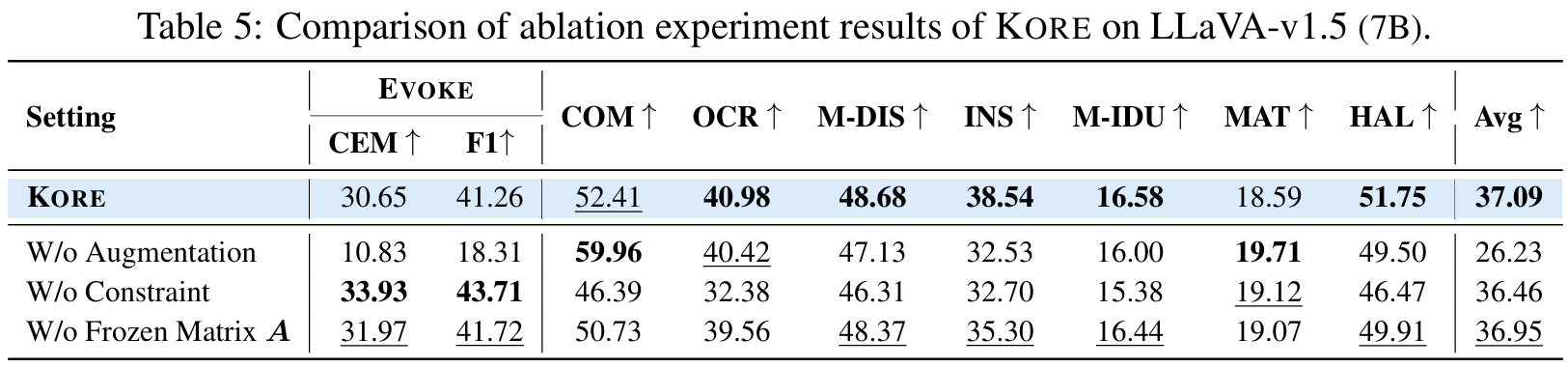
Analysis of Ablation Experiments
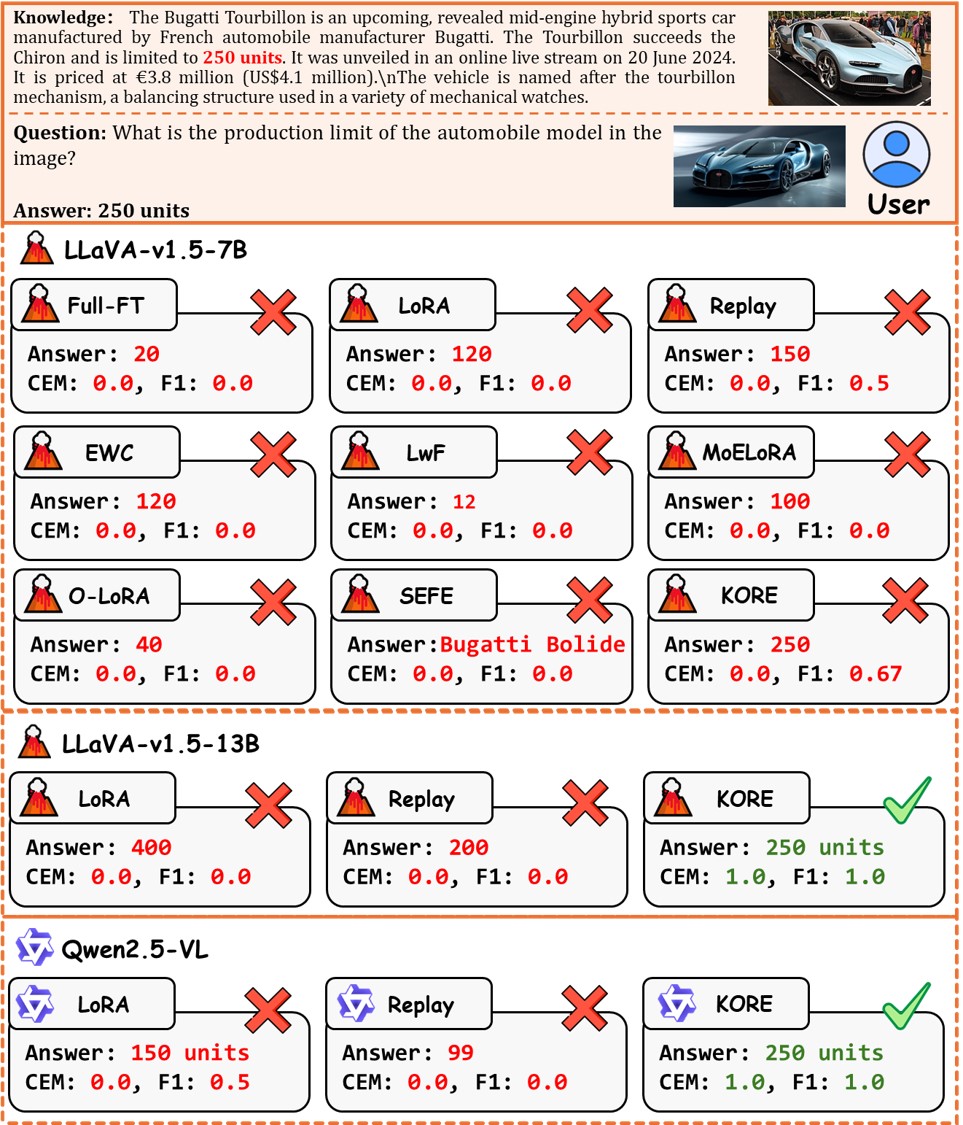
Qualitative Examples

Our Team










BibTeX
@article{jiang2025kore,
title = {KORE: Enhancing Knowledge Injection for Large Multimodal Models via Knowledge-Oriented Augmentations and Constraints},
author={Jiang, Kailin and Jiang, Hongbo and Jiang, Ning and Gao, Zhi and Bi, Jinhe and Ren, Yuchen and Li, Bin and Du, Yuntao and Liu, Lei and Li, Qing},
year = {2025}
}